Django REST Framework + Next.js (MUI) + Markdownでブログを作る【Part 2】
記事一覧へ
目次
前回までの振り返り
【Part 1】では各種基礎知識について学びました。【Part 2】では実際にDjango REST Framework(以下、DRF)部分の開発をしていきましょう。なおNext.js部分は【Part 3】でのご紹介となります。
環境構築
まずはDRFで開発するための環境を作っていきます。なお環境構築についてはDjango REST Frameworkの環境構築の記事で紹介したことがあるので細かい説明は省略しますが、ターミナルでの作業も一から実施していきます。
ディレクトリ作成〜DRFプロジェクトの作成
過去記事ではディレクトリ作成とプロジェクト作成をそれぞれ別のセクションで解説していましたが、ここでは早速省略します。
「一行解説」を見る
- (l.1-4) DRFプロジェクトを作成する箱を作成します。
- (l.6-11) 本プロジェクト用に環境を分けるため仮想環境を構築します。
- (l.13-17) 本プロジェクトに必要なパッケージ等インストールします。
- (l.27-30) Project(
blog_project)とApp(blog_app)を作成してDRFが始められるための準備をします。
ここまで完了すると、DRFプロジェクトのディレクトリは上の通りになっていると思います。
Project(blog_project)設定
環境構築が完了したら、はじめにProject(blog_project)側を設定していきましょう。
Project(blog_project)ではsettings.pyファイル→.envファイル→.gitignoreファイル→urls.pyファイルの順に編集します。
blog_project/settings.py + .env + .gitignore
blog_project/settings.py
blog_project/settings.pyの設定にあたって、まずは使用するライブラリをインストールします。
- python-decouple:設定項目をコード(今回の場合
blog_project/settings.py)から分離して参照させるために使用するモジュール。 - django-markdownx:DjangoでMarkdownエディタを使えるようにするライブラリ。
上の通りライブラリがインストールできたら、blog_project/settings.pyを編集していきます。
環境構築時、django-admin startproject コマンドでProject(blog_project)を作成するとblog_project/settings.pyにはすでにコードが書かれているので、「# 追記」とある行はそのまま新規入力、「# 修正前」・「# 修正後」と記載がある行では、「# 修正前」の行を削除し「# 修正後」の行を新規入力してください。特に大事だと思うポイントに絞って解説します。
「一行解説」を見る
- (l.6-7)
django-admin startprojectコマンド実行後、Djangoプロジェクトごとに生成される一意の秘密鍵です。Django起動時には必須のキーであるため、セキュリティ上の観点からconfigを利用して.envファイルを参照させることでSECRET_KEYの値を秘匿化しておきます。 - (l.9-10) DEBUG(モード)はDjangoプロジェクトにおいてエラーが発生した場合に詳細情報を提供してくれるものです。デフォルトでは
Trueとなっていますが、本番環境へのデプロイ時にはセキュリティ上の観点からFalseにしておく必要があります。SECRET_KEY同様、configを利用して.envファイルを参照させることでDEBUGの値を秘匿化しておきます。 - (l.12) Djangoプロジェクトを持つサイトを配信できるホストを指定するリストです。これにより、HTTPヘッダ・インジェクション(攻撃)を防ぐことができます。HTTPヘッダ・インジェクションについては、IPAの解説をご覧ください。
- (l.14-26)
INSTALLED_APPSはその名の通りDjango・DRFプロジェクトにおいてインストール済みのアプリ・ライブラリをまとめたリストです。- (l.15-20)
django.contribから始まるアプリはデフォルトで設定されているものです。それぞれパスを辿れば、後ほど作成するApp(blog_app)と同様の構造になっているのが確認できるはずです。 - (l.21-24) それぞれサードパーティのライブラリなので、
pipでインストール後に追記が必要になります。 - (l.25) App(
blog_app)名になりますが、こちらはblog_app/app.pyファイルの内の値を参照してください。
- (l.15-20)
- (l.31)
MIDDLEWAREとは、アプリケーション前後のリクエスト・レスポンスの処理が記載されているリストです。django-cors-headersをインストール後 (l.22) でcorsheadersを追加して、許可したオリジンからのリクエストのみに制限するオリジン間リソース共有(Cross-Origin Resource Sharing)を設定しましたが、それに関わる処理を実行するためにMIDDLEWAREにおいても上の通り追記が必要になります。なお (l.31) を除いた (l.30-36) のMIDDLEWAREはデフォルトで設定されています。 - (l.39)
CORS_ORIGIN_WHITELISTを設定することで、特定ドメインからのリクエストのみを許可できます。今回は、Next.jsプロジェクトからのリクエストのみを受け付けられるように、Next.jsが起動するローカルサーバのポート番号3000と設定しました。 - (l.41-43) ここでは、DRFプロジェクトのDRF設定を実施します。 (l.42) ではデフォルトの権限クラスを設定しています。
IsAuthenticatedという権限クラスをデフォルトで適用するよう記述しているので、views.pyファイルで設定されない限りは未認証のユーザーはAPIへのアクセスが制限されます。 - (l.63)
WSGIはWeb Server Gateway Interfaceの略語でウィスギーと読みます。従来、Djangoを含むWebフレームワークを利用する際には使用できるWebサーバが制限されていましたが、その問題を解決するためにWebアプリケーションとWebサーバを接続する標準仕様がWSGIによって定められました。WSGIに対応したWebアプリケーション(やフレームワーク)は、WSGIに対応した任意のWebサーバ上で運用できるようになるため、アプリケーション側がWSGIに対応していれば、アプリケーションのコードに修正を加えることなく、WSGI対応サーバを自由に選択することができます(※参考:Wiki)そしてこのDjango・DRFプロジェクト(一般用語では「Webアプリケーション」)がWSGIを介してWebサーバとやり取りする際の出入り口としてパスを指定するのが、WSGI_APPLICATION設定です。長々と解説しましたが、これもデフォルトで設定されています。なお、WSGI自体はアプリケーションサーバで動きますが、今回はgunicornの設定を想定しています。
.env + .gitignore
blog_project/settings.py設定時にも触れましたが、.envファイルで環境変数を設定します。まずは下のコマンドでファイルを作成しましょう。
ここで一緒に.gitignoreファイルも作成していますが、(こちらは今回説明は省略しますが、)GitHub等でコードを管理する場合に、GitHub上にプッシュしたくないディレクトリ・ファイルを定義するファイルです。せっかくなのでこちらも一緒に設定しましょう。
.envファイルには、blog_project/settings.pyで秘匿化したいSECRET_KEYとDEBUGについて記載します。
せっかく秘匿化したいのにGitにプッシュされてしまっては意味がないので、.gitignoreファイルでは、上のように記載します。他にも仮想環境のblog_virtualディレクトリ・キャッシュの__pycache__・データベース(以下、DB)のdb.sqlite3も記載しておきましょう。これでblog_project/settings.pyの設定は完了です。
blog_project/urls.py
続いて、blog_project/urls.pyの設定を実施します。このファイルでは、URLと関連するViewの紐付けを、urlpatternsというリストで定義します。
- (l.5) こちらはデフォルトで記載されているものですが、Djangoの管理サイトへアクセスするためのURLです。Django管理サイトではユーザー管理・データの登録更新削除等がGUIで可能です。
- (l.6) こちらは新規追加する行です。今回のDRFプロジェクトにおいてはAppとして
blog_appを作成しますが、blog_app/urls.py経由でblog_app内にあるView(blog_app/views.py)にアクセスするための設定をしています。パス名は自由に設定できますが、今回はブログ作成なので分かりやすくblog/としました。これで、Project(blog_project)側の設定は完了しました。続いて、App(blog_app)側の設定に移ります。
App(blog_app)設定
まずはApp(blog_app)側のディレクトリに移動して、必要なファイルを作成します。
ここではurls.pyファイルとserializers.pyファイルを作成しましょう。それぞれのファイルについての説明は各ファイルの設定欄にあります。
App(blog_app)では、models.pyファイル→serializers.pyファイル→views.pyファイル→urls.pyファイル→admin.pyファイルの順に編集します。
blog_app/models.py
blog_app/models.pyファイルは、DBのテーブルをPythonのクラスとして定義するためのファイルです。Djangoで提供されているModelクラスを継承して、DBテーブルのカラムと対応するフィールドを作成していきます。フィールド作成時にはフィールドの型を定義します。型には様々な種類がありますが、その中で今回利用するフィールドの型は以下の通りです。また型には一部必須のものも含めて()内にオプションを追加することができますが、それは後述します。
CharField():文字列(テキスト)データを入力できるフィールドです。最も一般的なフィールドと言っても良いでしょう。SlugField():URLの文字列を入力できるフィールドです。通常アルファベット・数字・ハイフンの組み合わせで構成され、スペースや特殊文字は利用しません。IntegerField():整数の値を入力できるフィールドです。数量を表現する際などに使われ、正・負・0を格納できます。ForeignKey():1対多(ManyToOne)の関係を表現できるフィールドです。一般的な外部キー参照フィールドです。ManyToManyField():多対多(ManyToMany)の関係を表現できるフィールドです。タグ付け等に利用できます。MarkdownxField():Markdown形式のテキストを入力できるフィールドです。今回のブログ作成の肝です。
上記フィールドの型を使ってModelを作成していきましょう。
「一行解説」を見る
- (l.1)
modelsをインポートします。 - (l.2)
blog_project/settings.py設定前にdjango-markdownxをインストールしましたが、その中からMarkdownxFieldをインポートして、デフォルトでは提供されていないMarkdownを記述できるフィールドの型を準備します。 - (l.4-9) l.1で
modelsをインポートしましたが、そのmodels.Modelを継承してModelを作成します。- (l.5) フィールド(名)として
f_categoryという変数を用意しCharFieldをインスタンス化します。CharFieldを利用する場合、max_lengthとして文字列の長さ指定が必須ですが、ここではNull値を許容するnull=Trueとデータ追加時の空白を許容するblank=Trueを加えます。特にnullオプションの設定については、一度Modelをマイグレーションしデータを追加した後に、さらにフィールドを追加する際に利用するものになります。 - (l.8-9) Django管理サイトにおける表示形式を定義しています。この場合、各データの
f_categoryフィールドに追加された値が表示されます。
- (l.5) フィールド(名)として
- (l.18-27) l.4-16では外部キーのModelを作成しましたが、ここからはブログのメインとなる記事のModel(
Entryモデル)を作成します。- (l.21)
bodyフィールドは、記事の本文としてMarkdown形式でテキストを入力するフィールドです。オプションは特に不要ですが、MarkdowxFieldを型として指定します。 - (l.22-23) (l.4-16) のModelをそれぞれ参照させます。 (l.22) では
ForeignKeyというフィールドの型を利用してFCategoryモデルを参照します。このフィールドではon_delete=models.SET_NULLをオプションに指定していますが、これにより親モデルであるFCategoryモデルが削除された場合でも、Entryモデル内のcategoryフィールドがnullに変わるためデータの整合性を保つことができます。また、同時にNull値を許容するためにもnull=Trueが設定されている必要があります。(l.23) ではManyToManyFieldというフィールドの型を利用してFTagモデルを参照します。 - (l.24) 下書きの記事データを非公開にするために
is_publickというフィールドを作成しています。IntegerFieldというフィールドの型とchoicesというオプションを利用することで、0を選択中の時には公開、1を選択中の時には非公開としています。
- (l.21)
説明が長くなりましたが、以上で、blog_project/settings.pyの設定完了です。
blog_app/serializers.py
blog_app/serializers.pyはDjangoにはないDRF特有のもので、作成したModel内のデータをJSON / XML形式に変換(シリアライズ)してAPIでレスポンスしたり、ユーザーから送られてくるJSON等の形式のデータをPythonオブジェクトに変換(デシリアライズ)したりする役割を持ちます。DjangoにおけるFormと考えてみてください。
「一行解説」を見る
- (l.1)
rest_frameworkからserializersをインポートします。 - (l.3)
blog_app/models.pyから作成したModelをインポートします。 - (l.5-13) メインの記事ではないModelについてSerializerを作成します。
serializers.ModelSerializerは、Serializerの中でも最も一般的なものと言っても良いでしょう。1) Djangoで作成したModelに対してしかシリアライズできない点、2) (l.6)class Meta内で動作を指定する点、が特徴です。※他にもserializers.Serializerというものもありますが、こちらはModel以外でもオブジェクトであればシリアライズ可能です。- (l.7) このクラス内でシリアライズした
FCategoryモデルを変数modelに格納します。 - (l.8) その
FCategoryモデル内のどのフィールドをシリアライズするか指定します。ここではすべてのフィールドを指定したいので__all__としますが、任意のフィールドのみ指定することもできます。
- (l.7) このクラス内でシリアライズした
- (l.15-25) 続いて、メインとなる
Entryモデルに対してシリアライズするよう設定していきます。EntryモデルはFCategoryモデルとFTagモデルを参照しているため、(l.16-17) の通り他のSerializerとは別の設定が必要になります。- (l.16) 対象の
Entryモデル内のcategoryフィールドに対して、(l.5) で作成したFCategorySerializerを指定します。 - (l.17)
tagフィールドについてはManyToManyのため、引数にmany=Trueを指定しましょう。 - (l.22-25)
lookup_field = 'slug'とした上でextra_kwargsで追加設定を付与しています。これによりEntryモデルの各レコードが、idではなくslugフィールドの値を使用してURLを構築するよう設定しています。他にもextra_kwargsでは指定したフィールドに対してread_onlyやwrite_onlyを指定することもできます。例えば、read_onlyを指定するとAPIでの読み込みは可能だが書き込みはできないようになるので意図しない更新を防ぐことができます。write_onlyについては、パスワード情報等の読み込みをすべきでないフィールドに対してよく使われます。
- (l.16) 対象の
blog_app/views.py
Serializerの作成後はView(blog_app/views.py)の編集です。DRFプロジェクトにおいては、APIエンドポイント(≒ URL)ごとに異なる振る舞い・ロジックを指定できます。ここまでの設定事項を整理し役割を明確化すると、Model(blog_app/models.py)からデータを取得後、Serializer(blog_app/serializers.py)でデータをJSON形式に変換し、View(blog_app/views.py)でレスポンスを生成するという流れになります。そのViewの数ですが、かなり多いので全部覚える必要はありませんが、「作成 / 取得 / 更新 / 削除」と「詳細 / 一覧」から必要に応じて使い分けする必要があります。今回は「一覧+詳細」の「取得」をしたいので、ListAPIViewとRetrieveAPIViewを使いましょう。
「一行解説」を見る
- (l.1)
ListAPIViewとRetrieveAPIViewはいずれもジェネリックビューに分類されるので、genericsをインポートしましょう。ちなみに、ジェネリックビュー(generics)は上の機能ごとにViewが提供されていますが、それ以外にも機能がまとめて提供されているビューセット(viewsets)というViewもあります。 - (l.2) 同じく
rest_frameworkから、今度はfiltersをインポートします。これによりクエリパラメータを使用してデータをフィルタリングすることができます。詳細は (l.23) で解説します。 - (l.8-16) メインの記事ではないModelについてのViewを作成します。
FCategoryモデル・FTagモデルともに一覧表示だけできれば良いので、ここではListAPIViewを利用します。- (l.9) まず
querysetを指定します。querysetとは、Viewがデータを取得・表示する際の元となるデータソースです。今回は各ModelをもとにしてViewを作成しているので、全レコードを取得するためにモデル名.objects.all()とします。 - (l.10) ViewがデータをシリアライズするためのSerializerを指定します。
blog_app/serializers.pyで設定したものを使いましょう。 - (l.11)
permission_classesを利用してアクセス制御をしています。blog_project/settings.pyの (l.42) でデフォルトのアクセス制御をかけてみましたが、今回はサンプルなので誰でもアクセスできる(AllowAny)を指定しましょう。
- (l.9) まず
- (l.23) (l.2) でインポートした
filtersについて、検索キーワードからフィルタリングできるようにするため、フィルターにはfilters.SearchFilterを設定します。なお、filters.OrderingFilterというフィルターを利用すると、並び替えができるようになります。 - (l.24) (l.23) で設定したフィルターにおいて、Model内のどのフィールドから検索するか指定します。ここでは
'title', 'slug', 'body'と設定したので、Entryモデルにおける対象のフィールドの中からフィルタリングができるようになります。 - (l.26)
Entryモデルにおいて、「詳細」の「取得」ができるよう設定します。 - (l.30)
RetrieveAPIViewは詳細情報の取得が可能であるため、識別子が必要になります。デフォルトではidでレコードを識別しますが、lookup_field = 'slug'とすることで、idの代わりにslugを識別子に変更できます。
blog_app/urls.py
続いてApp(blog_app)内でblog_app/urls.pyの設定をしましょう。こちらはProject(blog_project)側のblog_project/urls.pyとは別物です。
「一行解説」を見る
- (l.1) URLパターンを定義するために
path関数をインポートします。これにより各URLに対してどのViewを紐付けるか定義できます。第一引数にURLパターンの任意の文字列、第二引数にblog_app/views.pyで作成したViewクラスを指定します。 - (l.5-10)
urlpatternsリストにURLパターンを追加します。ここで各URL内のViewクラスに対して.as_view()メソッドを追加していますが、これはurlpatternsリスト内では関数しか指定できないので、.as_view()メソッドで関数ベースのViewに変換する必要があるためです。
blog_app/admin.py
こちらがApp(blog_app)側の最終ステップです。blog_app/admin.pyでは、Django・DRFプロジェクトの管理サイトの設定を行うためのファイルです。カスタマイズをすることで管理サイトにおけるデータの表示形式の変更等もできますが、今回はblog_app/models.pyで作成したModelを管理サイトに登録するだけにとどめておきます。これによって管理サイト上でのデータの表示追加更新削除が簡単にできるようになります。
「一行解説」を見る
- (l.5-7)
admin.site.register(モデル名)とすることで、管理サイトに簡単にModelを登録することができます。
これで今回のブログ作成のためのPythonファイル編集は完了しました。
共通
DRFプロジェクト作成の最終章です。ここではマイグレーション、データ入力、APIの動作確認を実施してDRFプロジェクト側の完成となります。
マイグレーション
マイグレーションとは、blog_app/models.pyで作成したModelをDBのスキーマ(構造)に反映させる作業です。今回Django標準のSQLiteというDBを使用していますが、現時点ではDB内にはデータもなければそのデータを入れる先のテーブルもカラムすらないので空っぽです。そのため、このマイグレーションという作業が必要になります。順番としては、まずmakemigrationsで「マイグレーションファイル」を作成してから、それをmigrateでDBに反映(マイグレーション)させるという流れです。
ターミナル
「一行解説」を見る
- (l.1-6) 上で説明したように、マイグレーションファイルを作成します。
- (l.1)
python manage.py makemigrationsでマイグレーションファイルを作成します。 - (l.3) すると、
blog_app/migrations/0001_initial.pyというパスで0001_initial.pyというファイルができたことが分かります。このファイルこそがマイグレーションファイルです。ちなみに、2回目以降マイグレーションを実施すると過去のマイグレーションファイルに対する差分という形で、例えば0002_xxx.pyという形式でマイグレーションファイルが作成されていきます。 - (l.4-6)
- Create model xxxとModelが3つ続いて表示され、それぞれがマイグレーションファイル内に作成されたことが分かります。
- (l.1)
- (l.7-29) 残りすべての行がDBへの反映部分です。
- (l.7)
python manage.py migrateで、0001_initial.pyをマイグレーションさせます。ここでマイグレーションファイルは指定しない場合には、blog_app/migrations/ディレクトリにあるすべてのマイグレーションファイルが反映されることになります。 - (l.8-9) 記載のAppについてマイグレーションが行われることが記載されています。ここで、「いや、
blog_app以外作ってないぞ!?」と思われたかもしれません。そんな方はよく思い出してください。blog_project/settings.pyのINSTALLED_APPSという項目で、デフォルトで設定されているアプリがあったことを。その中でDBへの反映が必要なデフォルトアプリは、各アプリ内ですでにマイグレーションファイルが作成されているので、このタイミングで一緒にマイグレーションされるわけです。下にもあるように、DRFプロジェクト作成後最初にローカルサーバを立ち上げた時に表示される、「18のマイグレーションファイルが適用されていません」、というのはこれのことだったんですね。ちなみに、これらのアプリはblog_virtual/lib/python3.10/site-packages/django/contrib内にそれぞれ格納されているので興味があれば確認してみてください。参考までに、以下DBにマイグレーションされるアプリの説明をまとめておきます。 admin:Djangoの管理者サイトに関連するアプリのマイグレーションです。管理者サイトの設定やログ記録などに関連するテーブルのスキーマ変更が含まれています。auth:ユーザー認証に関連するアプリのマイグレーションです。ユーザーやグループ、パーミッションなどの情報を管理するためのテーブルのスキーマ変更が含まれています。contenttypes:コンテンツタイプフレームワークに関連するマイグレーションです。Djangoアプリケーション内で使用されるModelとそのタイプに関する情報を管理するためのスキーマ変更が含まれています。sessions:セッション管理に関連するマイグレーションです。Webセッションのためのテーブルが作成され、セッションデータの保存に使用されるスキーマ変更が含まれています。- (l.10-29) ここからマイグレーションが走り、各マイグレーションファイルが
Applying xxx.000X... OKという形式で反映されていることが分かります。例えば (l.12) のマイグレーションファイルについてはblog_virtual/lib/python3.10/site-packages/django/contrib/admin/migrationsを覗けば見つかります。
blog_app/migrations/0001_initial.py
全てApplyされればマイグレーション完了ですが、ここで勉強のためにも作成したblog_app/migrations/0001_initial.pyというマイグレーションファイルの中身を確認してみましょう。
「一行解説」を見る
- (l.8) 今回初めて作成したマイグレーションファイルなので、
initial = Trueとなっています。2回目以降のファイルには表記はありません。 - (l.10-11) こちらも最初の作成なので
dependenciesリストの中身は空です。しかし、2回目以降の実施ではリストの中にタプル型で対象のAppとマイグレーションファイルが、('blog_app', '0001_initial.py')といった形式で記載されます。 - (l.13-42)
operationとはスキーマに対する変更内容がまとめられた部分になります。Modelを反映しているので当然ですがblog_app/models.pyと似たような表示になっていることが分かりますね。- (l.14) 今回は新規作成なので、
.CreateModelというメソッドが使われていることが分かります。他にも、Model自体が削除された場合には.DeleteModelメソッド、Model内でフィールドが追加された場合には.AddFieldメソッド、フィールドが削除された場合には.RemoveFieldメソッドが使われます。 - (l.17)
blog_app/models.pyでの設定項目との差分がありますね、idです。idはModel作成時には明示的に作成していませんでしたが、実は裏で作られているんですね。識別子がないとDBとして使えないので、当然は当然です。こちらはUUIDへの変更も可能です。
- (l.14) 今回は新規作成なので、
データ入力
DRFプロジェクトとしては一旦完成し、DBへの反映も終わったところで、早速データを入力していきましょう。いつも通りpython manage.py runserverでローカルサーバを立ち上げてください。すると(画像ではblog/のパスを開いてしまっていますが、)画像下赤枠の通りadmin/というパスとその他にblog_app/urls.pyファイルで作成したblog/が先頭についたパスがいくつかあるのが分かります。
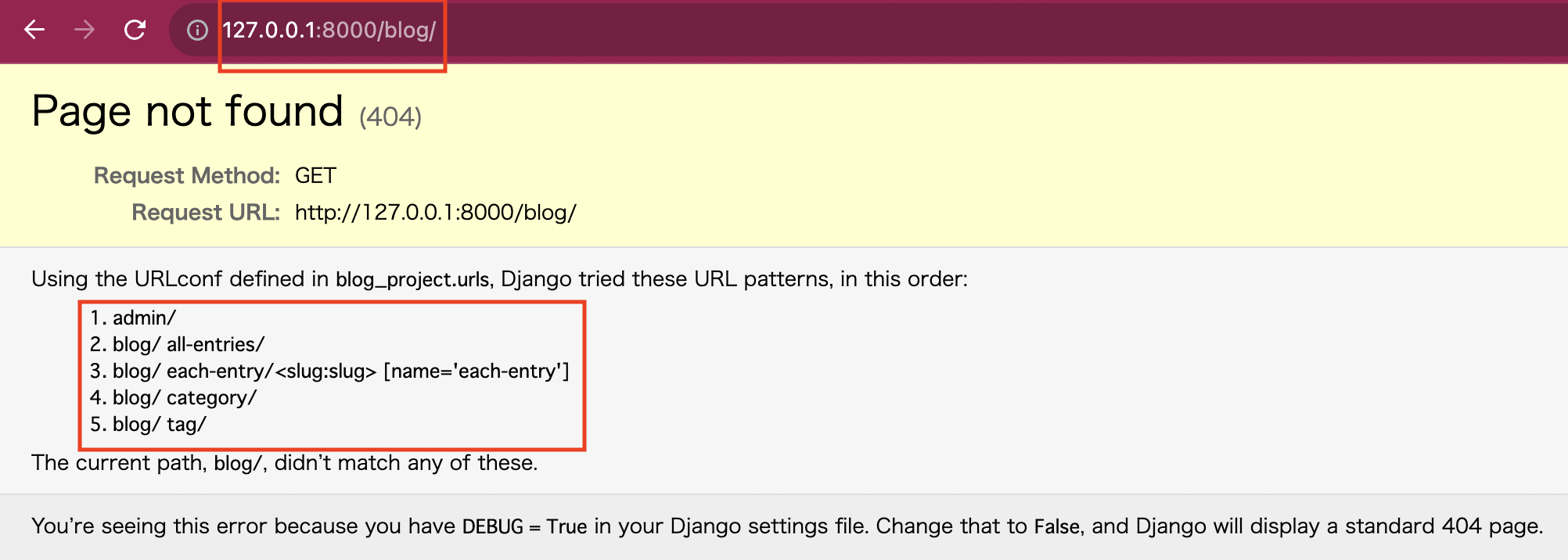
admin/から管理サイトにいきたいところですが、admin/パスに遷移するとusernameとpasswordが求められると思います。でも作った覚えがないですよね?そうです、作らないといけないのです。下のようにターミナルに戻って下の順序通り作りましょう。
「一行解説」を見る
- (l.1)
python manage.py createsuperuserとコマンドを入力すると、最も強い権限を持つスーパーユーザーが作れます。 - (l.2) デフォルトでは
xxとなっていますが、ここではblog_posterという名前で作ってみます。 - (l.3) メールアドレスの入力ができますが、こちらの入力は任意です。
- (l.4-5) パスワードとそれの繰り返しを実行します。
- (l.6) スーパーユーザーができました。こちらで設定した項目を
admin/の画面で入力してください。下の画像の通り管理サイトにログインできるはずです。
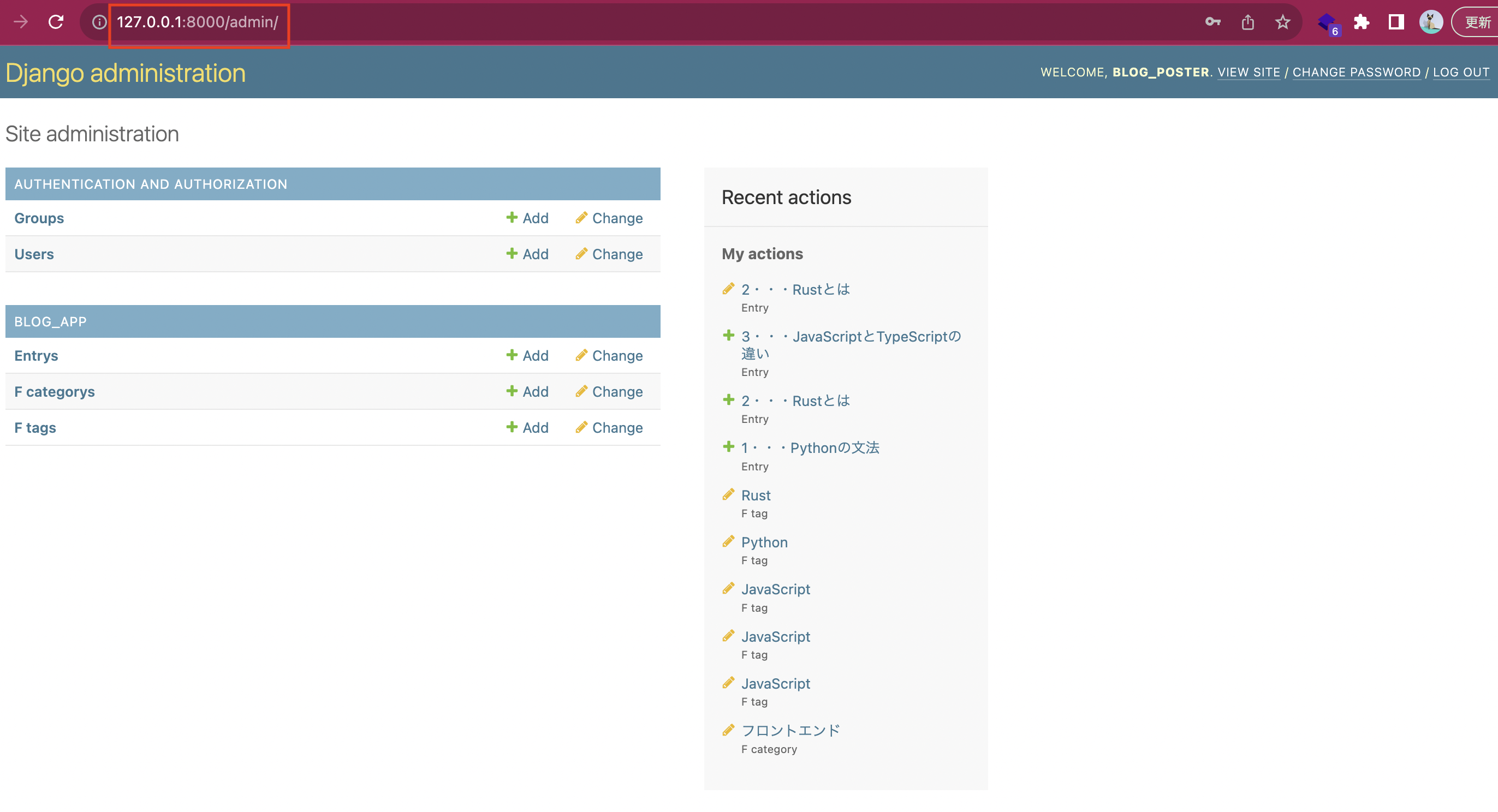 ここでデータを3つほど入力してみます。入力したら次はAPIの動作確認です。
ここでデータを3つほど入力してみます。入力したら次はAPIの動作確認です。
APIの動作確認
ここではAPIの動作確認ということで、blog_app/urls.pyファイルで作成した全てのURLにアクセスしてみます。blog_app/urls.pyファイルで設定した通り各URLはViewと接続しているので、問題なく各リソースにアクセスできれば、今回は一旦動作確認完了としたいと思います。
それでは、まず/blog/all-entriesにアクセスします。入力したデータが下画像の通り確認できると思います。
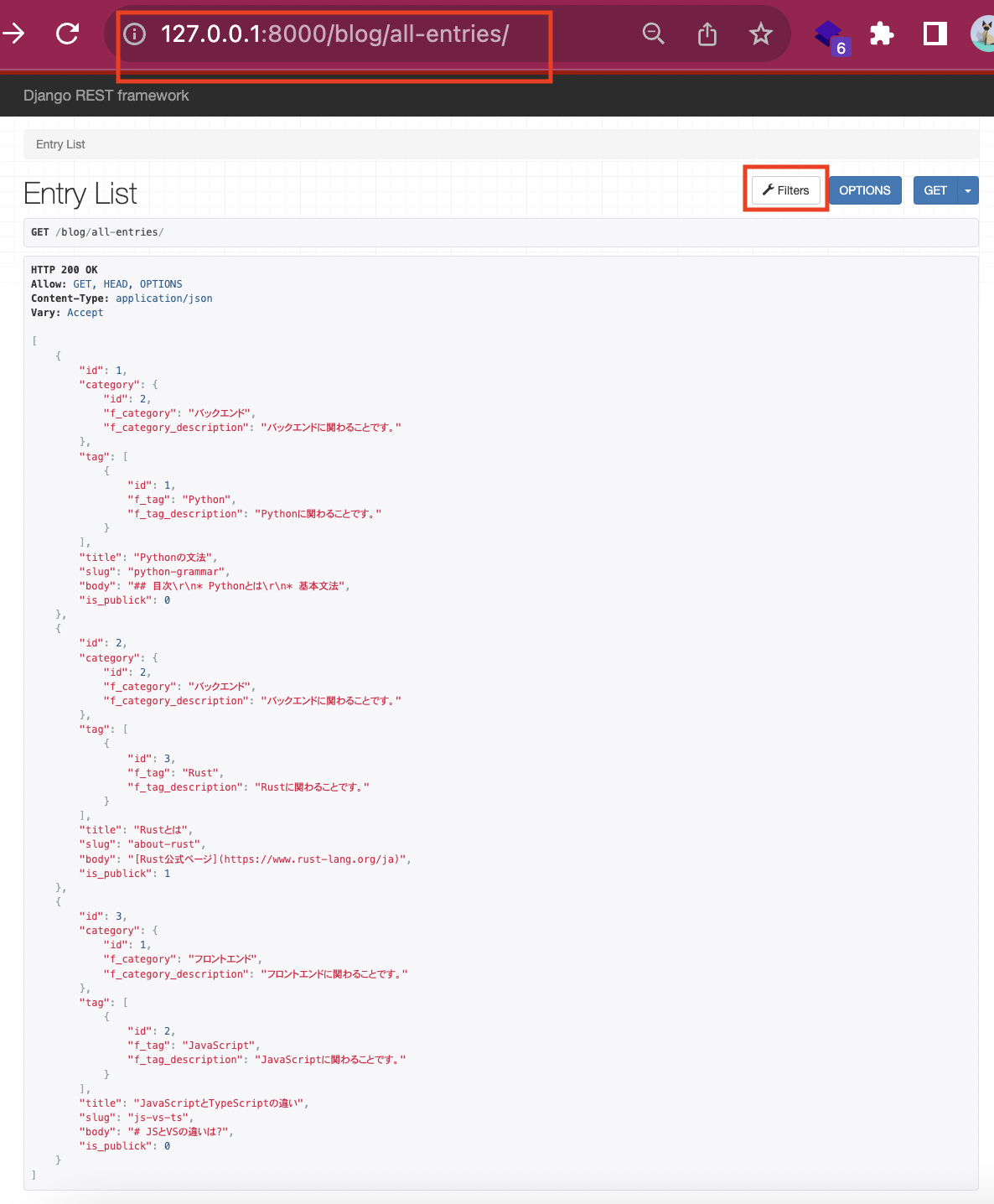
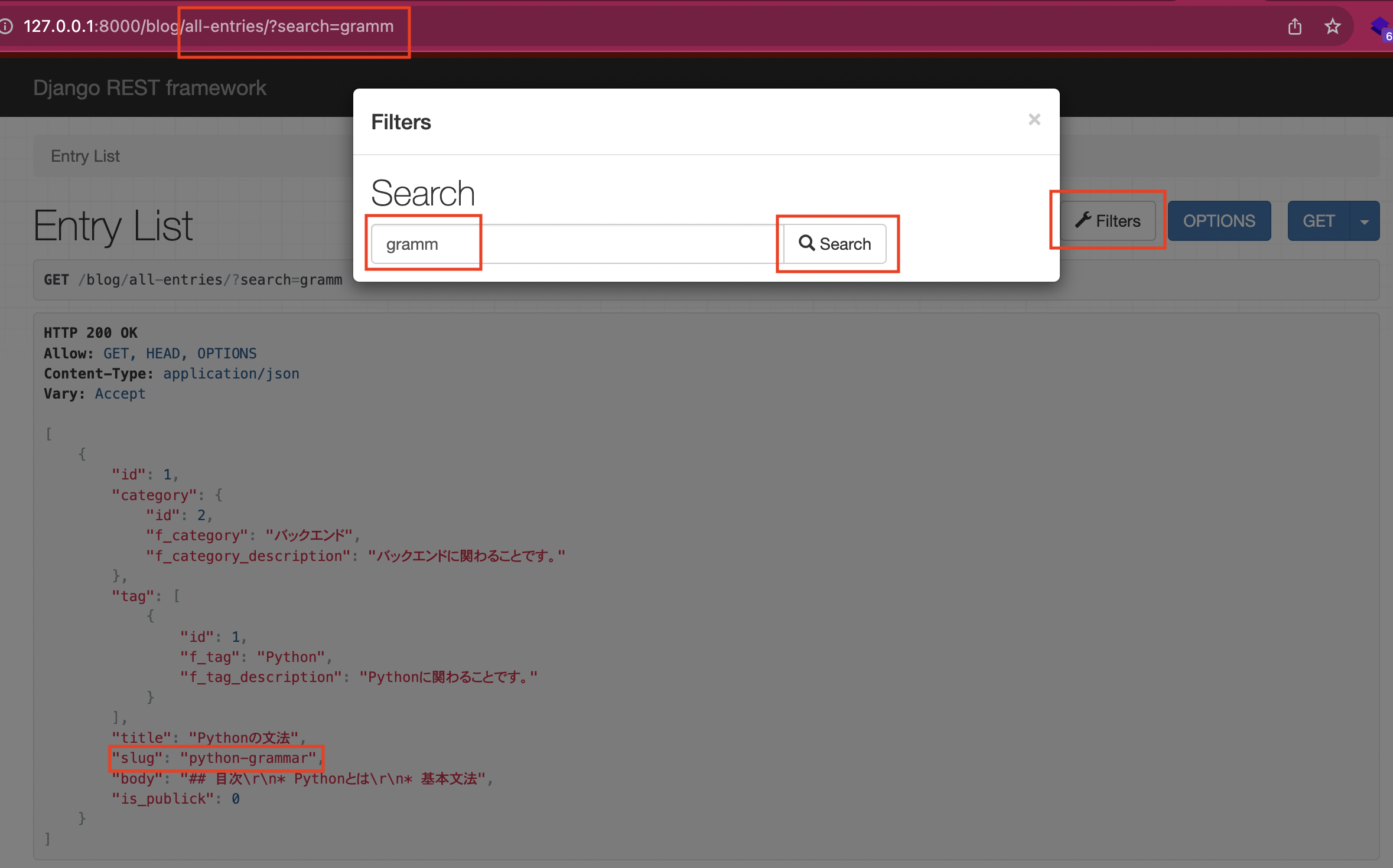
Filltersというボタンがありますが、これを押すと下画像のようにダイアログが表示されると思います。blog_app/views.pyでfilters.SearchFilterを使って検索キーワードによるフィルタリングを実装しましたが、それの動作確認のためにダイアログには"gramm"という文字列を入力してみました。Searchボタンを押してみると、1件だけレコードが引っかかったようです。レスポンスを見るとslugにpython-grammerと登録していたのですが、blog_app/views.pyではslugも検索対象にするよう設定していたので、これがフィルタリングされ表示されたようですね。これで問題なくフィルタリング機能が実装されていることが確認できました。ちなみに検索をすると表示のようなURL(/?search=検索キーワード)に変わっていることが分かります。
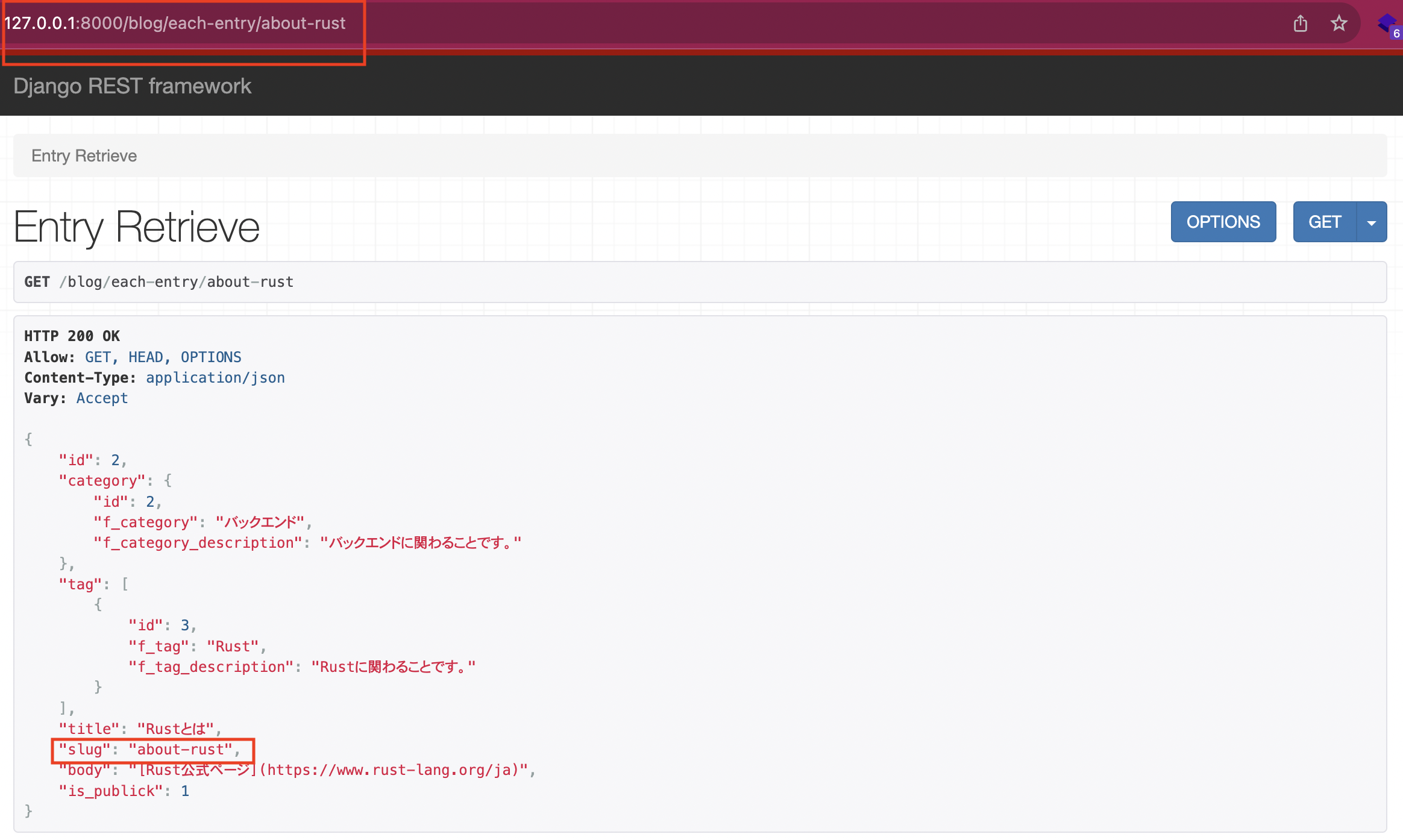
"id": 2にある通りRustについての記事を作成しています。このデータのslugであるabout-rustを取ってきて、/blog/each-entry/の後に付けてアクセスしましょう。すると、下の画像の通り詳細情報が表示されたと思います。問題なくアクセスできましたね。
まとめ
DRFプロジェクト側の設定、お疲れ様でした。続いて、Next.jsプロジェクト側の設定に移りましょう。
記事をシェアする
記事一覧へ